The first step in the journey to excellent and efficient emergency response begins with an evaluation of the status quo. In many cases, incident response teams find their way into a particular pattern of responding (either good or bad) and tend to stick with it. Patterns and habits, by their very nature, are comfortable to maintain and difficult to break. Regardless of whether you are happy with the way you and/or your team responds to IT emergencies, it is wise to at least investigate if improvements can be made or efficiencies can be gained. The most successful and smoothly operating response teams share common characteristics, all of which are easy to identify once you know what to look for. Separate and apart from an After Action Review (AAR), which takes place after the response, it may be useful for you to evaluate your emergency response process, as it currently exists and see if there are areas of improvement. Keep in mind that efficient incident response is all about process, with seven general but distinct steps in the Incident Lifecycle:
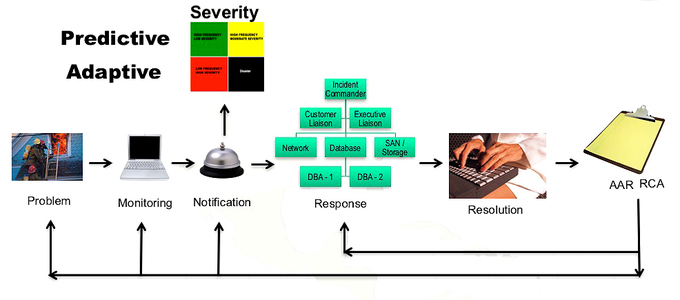
You may see a list in a different order, or perhaps with a different step here or there, but for the most part, this is how an IT incident evolves. Figure 1-1 depicts the Incident Lifecycle. QA and QI are part of the AAR process, and not called out as a separate item here.
- Detection of the problem
- Information gathering through monitoring tools
- Notification/Assembly of the response team
- Problem solving (response)
- Incident resolution
- After Action Reviews (AAR)
- *Quality Improvement (QI) and Quality Assurance (QA)
You may see a list in a different order, or perhaps with a different step here or there, but for the most part, this is how an IT incident evolves. Figure 1-1 depicts the Incident Lifecycle. QA and QI are part of the AAR process, and not called out as a separate item here.
We commonly run into incident response teams that have been out scaled by a problem that became bigger and faster than how quickly the right problem solvers could be assembled, or find frustration in the fact that only a few incident responders are “capable of running an incident”, or that there is lack of clear and directed leadership and chaos ensues either on the conference bridge or some other communication channel. Whatever the reason, if you are looking for a better way, it’s important to understand why your current way isn’t working as well as you might like.
You’ll notice we have used all capital letters to spell PROCESS. This is no mistake. We have developed an acronym that represents the 7 key attributes of any incident response program management.
You’ll notice we have used all capital letters to spell PROCESS. This is no mistake. We have developed an acronym that represents the 7 key attributes of any incident response program management.
Predictable
Repeatable
Optimized
Clear
Evaluated
Scalable
Sustainable
To that end, use PROCESS as a step-by-step analysis tool. List each first letter and think through how well your response mechanism meets that initiative. The questions asked will differ from company to company, and there isn’t really a cookbook approach. It’s more of a thought exercise to work through the various aspects of a PROCESS driven response team, and to see where you may find weakness or areas of improvement in your system!
Predictable
The foundation of any excellent incident response team is predictability. Predictability in this sense is really about the Wartime org chart. Is there an identified core group of responders and does everyone know his or her role and responsibility when dispatched to an incident? Are your technical experts on call in different time zones? Are there back-ups to the primary on call personnel and are they clear that ‘on-call’ means ready to respond to a page or text or some other notification in a time frame specified by the company? Is there clarity about roles and responsibilities and the expected behavior of each person once they are assembled? Are the expectations for technical experts, the leadership (IC) and the timeframes for response clearly identified and more importantly followed and enforced? Emergency response isn’t about arriving to help solve the problem when it’s convenient. Incident response is not optional because your regular day job keeps you crazy busy each day. If you are “on duty” or “on call” and identified as a responder, ensure you are ready to respond quickly. Be ready, willing and able to answer the call and protect the business! Ensuring that response expectations are clear is low hanging fruit in terms of ensuring the response mechanism is functioning properly because it all can be done in advance of the incident occurring. Identifying the players, or at least the type of players you may need is a pre-planning exercise, and can be largely scripted out during Peacetime, deployed during Wartime, and evaluated/refined as part of the AAR. Think about your last 10 incidents and decide if the response to each was as efficient as it could have been. Did each incident have a predictable incident response? Did you get the right people quickly and were they ready to participate in a positive way?
Repeatable
If there is uncertainty about who will respond to an incident or who will be in charge, your response mechanism isn’t predictable and repeatable. Many organizations have thought through and identified a certain list of incident types, assigned them a severity level, and matched the responder notifications to those severity levels. Repeatability is all about consistently notifying the right people identified in the predictability section. As an example, a SEV level 1 may have a predetermined list of whatever technical expertise would be appropriate for that particular problem. Each organization is different, so we aren’t going to try to provide examples, but suffice it to say that timely identification of a problem, that transitions to a rapid and specific call out procedure with expectations on when the technical experts and the incident commander will get together (the quicker the better for certain) is the keystone to predictability. Any response mechanism to any type of problem should strive to be the same no matter what day of the week, time of day or time of year the problem occurs. Predictable and repeatable response will happen the same way at 2 o’clock on Christmas morning as it does on any day during normal business hours. This is not to say that an organization should have 24/7 operations to qualify for a repeatable response. It is to say that when there is a possibility that a failure could require an incident response, whatever your operating hours may be, your incident response team should be clearly ready to go each and every minute of that window of time.
Optimized
Optimization in this setting is about taking the necessary steps to build upon a predictable and repeatable response mechanism by ensuring the identified human resources are trained, equipped and clearly prepared to do what is being asked of them. This piece of PROCESS is about spelling out the rules of engagement for the responders. Are there clear escalation policies in place, and to whom would issues get escalated? Do you have a formal training program for responders (and we hope it’s based on IMS!), and is it provided consistently across your team, especially if the team is global. Does your team respond consistently, meaning that all needed technical talent knows how to enter, participate and assist whether it’s on a conference bridge or some other form of communication? Is the concept of incident command universally understood and implemented? It’s fairly easy to spot those individuals that just “don’t get it” in terms of having the sense of urgency and focus required to solve the problem, or feeling inconvenienced by being on call in the first place. Emergency response is a team sport, and there is no room for ego’s or attitude or lack of trust within the team. In our consulting practice, we emphasize the need to identify all the potential IC’s technical experts, executives, vendors, etc., that may be called to respond and ensure that they all have specific response training and a clear understating of the expectations so that at minimum, each responder knows what is expected of them and they are prepared to contribute appropriately.
Clear
Clarity of purpose and expectation of the responders seems simple, but is oftentimes overlooked. It’s easy to assume that all persons who may join a response in whatever capacity, would be clear about the goals and objectives. Unfortunately, this isn’t always the case. The burden of clarity, or the how’s and why’s of the company’s incident response needs, usually falls to whoever is responsible to lead and manage the overall program. Managing the incident response program is about ensuring predictability, repeatability and optimization. Leading the program is about ensuring clarity of the mission of the response team and how the responders function as a team. To that end, it’s absolutely vital that all responders know and understand what’s expected of them when they are called upon to respond, and the consistency in which the team responds is ensured. The nature of the IT emergency can and will vary, but the emergency response approach should be clear and consistent. Do all responders really understand they are in essence functioning as the ‘Fire Department’ for the company? We hear many Fire Department related references from site reliability engineers, technical experts, and executives. What’s strange is that many responders don’t see the public safety responder to IT responder connection, and the sense of responsibility that goes along with it. “We are so busy putting out fires”, said one engineer,” that I can’t find time to do my day job!” The use of the word ‘triage’ is commonly used in IT. Its origin is as a common medical term, meaning to sort and assign priority during an incident where many victims may be found. This concept clearly translates to IT, but the sense of urgency or the realization the emergency response is emergency response, regardless of the type of emergency, seems to be lost to some degree in IT. Think of the point of clarity in this way; we all don’t need to think the same way during a response, but we must think in the same direction with the same viewpoint unity of purpose methodology and focus.
Evaluated
Up to this point, the emphasis has been on putting the pieces in place to create an excellent emergency response program. The evaluation piece is where the QA and QI efforts enter in to the PROCESS of building a resilient and efficient emergency response mechanism comes in. Emergency response is a dynamic effort typically occurring under dynamic circumstances and as such, constantly point out areas that could use improvement. We will discuss the AAR process in Chapter 4, but for now understand that each incident response creates an opportunity to learn from the incident in order to better respond to the next incident. A commitment in time and effort to objectively and specifically look at the detection of the problem; notification of the incident responders; assembly of the incident response team; the problem solving effort and how the incident was ultimately resolved will most certainly offer some lessons learned or areas that could be improved. The key point is that QA and QI is an investment, and that investment will produce the dividends over the long run. Tweaking the incident response process, or the way in which the technical experts dissected a problem, or the leadership abilities of the Incident Commander may uncover some weaknesses that may be hampering your pursuit of excellent performance.
Quality Assurance (QA): Taking an objective look at a behavior, decision or circumstance, evaluating it against the established standard, and ensuring the expected behavior is occurring.
Quality Improvement (QI): Finding opportunities, weakness or missing pieces of the response mechanism and taking steps to correct/improve the deficiency.
It’s all about getting better – not finding blame!
And while you may uncover some uncomfortable ‘landmines’ of poor or inconsistent performance or other aspect of the incident response PROCESS, it’s better to identify them, acknowledge them and do what it takes to improve the deficiency. Absent any thoughtful way of objectively evaluating the incident response PROCESS, poor performance may become the established norm and culturally, it will be more difficult to change down the road.
Quality Assurance (QA): Taking an objective look at a behavior, decision or circumstance, evaluating it against the established standard, and ensuring the expected behavior is occurring.
Quality Improvement (QI): Finding opportunities, weakness or missing pieces of the response mechanism and taking steps to correct/improve the deficiency.
It’s all about getting better – not finding blame!
And while you may uncover some uncomfortable ‘landmines’ of poor or inconsistent performance or other aspect of the incident response PROCESS, it’s better to identify them, acknowledge them and do what it takes to improve the deficiency. Absent any thoughtful way of objectively evaluating the incident response PROCESS, poor performance may become the established norm and culturally, it will be more difficult to change down the road.
Scalable
This part of PROCESS is somewhat linked to predictability and repeatability in that a sound incident response PROCESS is built in such as way that it can quickly grow or shrink depending on the needs of a particular incident or the based on the growth of the organization. The latter refers to scalability at a program level rather than incident level, but is important in that as the organization grows, so grows the need for comparable response. We refer to this as ‘bench strength’ much like how sports teams look at scaling, or having access to a wide variety of equally good talent to fill in the gaps for rotating, resting or replacing injured players. For IT, it’s important to acknowledge vacations, sick time, travel, shift coverage, etc. in order to maintain a high level of proficiency at all times. Since it’s unknown when the big crippling incident might strike, the IT incident response process should be ever at the ready, much like a fire department,. A team with good bench strength does not just have a handful of star players. It is comprised of a corps of talent that can be interchanged, or added, or expanded in some way to meet whatever need is present. We find that IT service providers are processing phenomenal amounts of electronic transactions every minute of every day and by all account, IT does not appear to be a shrinking industry. Therefore, environments will get more complex, and larger and consequently fail harder and with more complexity as time goes on. Many IT environments are already so complex it takes a constellation of specific expertise to understand the various operational aspects. It’s quite common to require entire Dev teams, or application teams, or deep technical experts in database, or storage or network to assemble as a team to solve an IT issue. And with scale and complexity come even more specialization and the need to perhaps handle a larger volume of IT incidents and/or larger and more complex incidents happening concurrently. Our point here is that having the ability to rapidly notify and obtain more/different/more qualified etc. technical experts, and/or quickly expand the team in general to accommodate company growth will help to build a culture of respond within the organization. Ideally, the team establishes its identity in such as way that it is not dependent on only a handful of people to respond on a regular basis, creating a situation whereby the responders are getting burned out, or cannot grow the ability to respond concurrent with the growth and/or complexity of the environment.
Sustainable
When incident response transitions past the point of initial training and becomes a formal activity within an organization, there comes a time when the organization must view, care for, and place value on the incident response team just like any other business unit. If the sales team of an organization needs to grow, or loses talent, or needs to adjust strategy based on a change in business direction or philosophy, the company responds by addressing those issues rapidly, or it runs the risk of financial loss. Incident response is just a valuable as any other business unit, and deserves the same amount of financial commitment, personal attention and organizational development. Incident response in the IT field should not be viewed as a ‘necessary evil’ as we have seen in many organizations. Being on duty to respond should be cultivated as an honor within the organization, and intended to attract awesome and skilled talent. Incident response duty is painful sometimes – who likes to get up in the middle of the night on a regular basis – but in essence this inconvenience is absolutely critical to the continual health and well being of the organization. We say all this to underscore this point of sustainability. Incident response and those who perform it are vital to an organization and in order to attract and retain great people to do it, the organization must place value on the endeavor. Few in the IT incident response business received any formal training on becoming an incident responder. Rather, individual technical skill, or unique knowledge of an operating environment naturally leads them to the ‘tip of the spear’ in incident response. Operations, specifically incident response as part of Operations, is the place where technology and failure intersect, and the resolution process must be efficient in order to keep the organization flourishing. To that end, it is more common to take great technical talent and bolt on incident response training at some point and anoint the person as an incident responder, whether they are good at the incident response function or not. Many times this approach works well and individuals make a smooth transition from technical expert, to an incident response technical expert, which are not necessarily the same thing. Again, establishing the culture of incident response, and having a programmatic viewpoint on looking after the team with support, leadership and financial commitment will make attracting and keeping great talent a much easier task.
Summary
- PROCESS is an acronym you can use as a programmatic evaluation tool. Using each point as a point to guide a discussion about the various aspects of your incident response process can help provide insights into areas you may be able to improve.
- Any incident response process mechanism must be Predictable to ensure maximum efficiency
- You should be able to respond the same way, every minute of every business hour.
- Team members should be trained, equipped and ready to do the job the company is asking them to do.
- Everyone on the incident response team should know exactly: what is expected of them; what their role is; what latitude they have to make decisions on an incident; and know they have support from executive leadership to solve problems on behalf of the organization.
- Good incident response process can rapidly scale and de-escalate to match the needs of the incident.
- Solid incident response programs are built to be sustainable in terms of recruiting the best talent and keeping them.
- An organization should build and maintain a culture of response and view it as important as any other business unit.
 RSS Feed
RSS Feed